Definiowanie postaci skorowidza
Wstęp
Każda poważna publikacja o charakterze naukowo-technicznym powinna posiadać skorowidz (indeks), czyli uporządkowany wykaz używanych, bądź definiowanych pojęć, zawierający informacje na jakich stronach są one używane.Jedną z zalet TeX-a jest możliwość automatycznego tworzenia zbiorów dodatkowych, zawierających informacje związane z przetwarzanym tekstem. Utworzony zbiór możemy przetworzyć innym programem; przy ponownym uruchomieniu TeX-a może on zostać dołączony do dokumentu podstawowego.
Do porządkowania zbioru haseł służy program plmindex
(lub makeindex).
Opisując proces tworzenia skorowidza powołuję się na swoją
implementację; program plmindex, czyli
Polish (Multilanguage) index. Program może być zastosowany
do budowy skorowidza w polskich publikacjach. Dokładny
opis własności programu plmindex znajduje
się w następnym artykule tego cyklu.
Schemat przetwarzania
Tworzenie skorowidza w dokumencie przetwarzanym TeX-em
zostało zrealizowane według powyższego schematu zilustrowanego
rysunkiem:
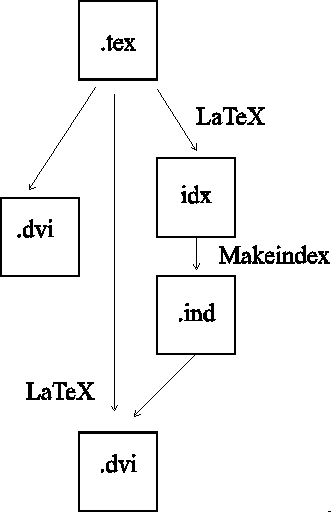
Po pierwszym przetwarzaniu dokumentu otrzymujemy zbiór
dodatkowy z rozszerzeniem .idx (podstawowy trzon
nazwy jest identyczny z nazwą dokumentu). Zawiera on wszystkie
hasła, definiowane w dokumencie źródłowym za pomocą
polecenia \index. W celu zainicjowania zbioru haseł
należy wywołać polecenie \plmindex
Podstawową rolą programu plmindex jest uporządkowanie i
posortowanie zbioru haseł wygenerowanego przez pakiet LaTeX-a.
Uporządkowany zbiór skorowidza
dołączamy do dokumentu podstawowego poleceniem \printindex.
Standardowo zbiór ten ma rozszerzenie .ind.
Tworzenie zbioru haseł
Niezbędny zestaw poleceń w dokumencie umożliwiający utworzenie
i dołączenie skorowidza:
\documentclass{article}
\usepackage{makeidx}
\makeindex
\begin{document}
.
.
.
..... bqq\index{bqq}
.... aqq\index{aqq}
.
.
.
\printindex
\end{document}
Po przetworzeniu pakietem LaTeX2e otrzymamy następujący zbiór skorowidza:
\indexentry{bqq}{1}
\indexentry{aqq}{1}
Poszczególne hasła sa definiowane poleceniem \index{...}.
Najwygodniej jest umieszczać polecenia tworzące hasła w momencie
pisania dokumentu. Trudno sobie wyobrazić automat wprowadzający
wskazane słowa do skorowidza, ponieważ hasła powinny występować
w swojej podstawowej formie (np. rzeczowniki w mianowniku), a nie
w formie wynikającej z kontekstu; pozostaje ,,ręczne'' definiowanie
hasła przy okazji jego istotnego wystąpienia.
W zbiorze haseł
każde zdefiniowane pojęcie jest umieszczane jako pierwszy argument polecenia
\indexentry, drugim argumentem jest numer strony na
której ono wystąpiło (wg. aktualnego formatu pisania numerów stron).
Należy dbać o to, aby między wystąpieniem danego hasła, a
poleceniem wprowadzającym je do skorowidza nie nastąpiło przejście
do nowej strony.
| definicja błędna | definicja poprawna |
aqq \index{aqq}
| aqq\index{aqq}
|
Przetwarzanie zbioru haseł
Zbiór zawierający listę wszystkich haseł należy przetworzyć programem plmindex. W najprostszym przypadku linia wywołania programu wygląda następująco:plmindex zbiórHasła definiowane w zbiorze zbiór
.idx zostaną
pogrupowane (usunięte wielokrotne definicje na tej samej stronie)
oraz posortowane i zapisane do zbioru zbiór.ind.
W naszym przykładzie,
uporządkowany zbiór (rozszerzenie .ind)
będzie wyglądał następująco:
\begin{theindex}
\item aqq, 1
\indexspace
\item bqq, 1
\end{theindex}
Podczas powtórnego przetwarzania dokumentu pakietem LaTeX2e, powyższy zbiór
zostanie dołączony w miejscu wystąpienia polecenia \printindex.
Skorowidz wielopoziomowy
Program plmindex pozwala na zdefiniowanie trójpoziomowej struktury hasła. Znakiem odzielającym poziomy jest! (wykrzyknik). Przykładowe
polecenia:
krowa\index{ssaki!parzysto-kopytne!krowa}
koń\index{ssaki!nieparzysto-kopytne!koń}
tapir\index{ssaki!nieparzysto-kopytne!tapir}
są ssakami\index{ssaki}
określenia: parzysto-kopytne i nieparzysto-kopytne
są hasłami podrzędnymi hasła ssaki i samodzielnie
nie wystąpują (nie są definiowane w sposób jawny). Nazwy krowa,
koń i tapir
stanowią najniższy poziom.
Po przetworzeniu programem plmindex zbiór .ind wygląda następująco:
\begin{theindex}
\item ssaki, 1
\subitem nieparzysto-kopytne
\subsubitem koń, 1
\subsubitem tapir, 1
\subitem parzysto-kopytne
\subsubitem krowa, 1
\end{theindex}
Numery stron są umieszczane tylko wtedy jeśli hasło jest wprowadzone
w sposób jawny do indeksu (np.
hasło parzysto-kopytne zostanie utworzone automatycznie,
i nie zostanie opatrzone numerem strony).
Ostatecznie po wydrukowaniu powyższy fragment skorowidza wygląda
następująco:

Zmiana kolejności sortowania
Czasami zdarza się, że hasło powinno być umieszczone w innym miejscu
niż wynika to z porządku leksykograficznego (np. polecenie
TeX-a poprzedzone znakiem \ umieszczamy w miejscu
wynikającym z nazwy polecenia, ignorując znak \). W tym wypadku
polecenie \index ma następującą skladnię:
\index{hasło do sortowania@hasło do indeksu}
określenie
hasło do sortowania służy programowi plmindex jako wzorzec do nadania
porządku leksykograficznego, natomiast hasło do indeksu
znajdzie się w spisie. W przypadku haseł wielopoziomowych
polecenie może wyglądać następująco:
\index{sort@index!sort-1@index-1!sort-2@index-2}
Innym powodem użycia tej konstrukcji może być chęć zmiany kroju
pisma jakim składane jest dane hasło (np. wyróżnienie słowa kluczowego):
\index{alfa@{\itshape alfa}}
Zbiór .ind wygląda następująco:
\begin{theindex}
\item {\itshape alfa}, 1
\end{theindex}
Odsyłacze w skorowidzu, efekty dodatkowe
Definiując hasło skorowidza, możemy w tym momencie zwrócić uwagę czytelnika na inne hasło, służy do tego operator encapsulacji, którym jest znak|.Przykład:
\def\seename{p.}
\def\see#1#2{#2, ({\itshape \seename~#1}\/)}
aqq\index{aqq|see{bqq}}
da nam następujące hasło w skorowidzu:
\item aqq, \see{bqq}{1}
które w dokumencie wynikowym, będzie wyglądało następująco:
- aqq, 1, (p. bqq)
| jest traktowany
jako makropolecenie (jego argumentem aktualnym jest zawsze numer strony).
W przypadku konstrukcji see definiowany jest własny parametr
określający hasło podobne -- parametr drugi (numer strony) jest pobierany
z listy parametrów aktualnych, ale nie jest wykorzystywany
(w przeciwnym wypadku pojawiłby się jako blok {1}.
Za pomocą enkapsulacji można zrealizować rozróżnianie typu występującego hasła, np. miejsce definicji odróżniamy od normalnego wystąpienia użyciem innej czcionki przy podawaniu numeru strony; i tak:
- italic hasło używane w przykładzie
- bold miejsce zdefniowania pojęcia
- pozostałe składane czcionką standardową
- bold miejsce zdefniowania pojęcia
\def\italic#1{{\itshape #1}}
\def\bold#1{{\bfseries #1}}
\def\idxb#1{\index{#1|bold}}
\def\idxi#1{\index{#1|italic}}
\let\idx=\index
aqq\idxb{aqq} %miejsce definicji
aqq\idx{aqq} %normalne wystąpienie
aqq\idxi{aqq} %użycie w przykładzie
i rezultat:
\item aqq, 1, \bold{1}, \italic{1}
Grupowanie numerów stron
Używając polecenia\index możemy zadeklarować, że
dane hasło jest opisywane na kilku stronach. Początek
opisu hasła zaznaczamy:
strona 1: aqq\index{aqq|(}
a kończymy
strona 3: aqq\index{aqq|)}
w wyniku działania programu plmindex i ponownego przetwarzania LaTeX-em
otrzymamy:
aqq, 1-3
jeżeli między konstrukcją
\index{...|(}, a \index...|)}
pojawi się normalna definicja tego samego hasła to zostanie
ona zignorowana (jako zawierająca się w zadanym zakresie). Jeżeli konstrukcja
zamykająca nie wystąpi, to ostatnia definicja hasła spełni tą rolę.
Standardowo, jeżeli hasło występuje na kolejnych stronach to
numery stron są grupowane (efekt taki jak w powyższym przykładzie).
Używanie powyższej
konstrukcji ma sens, jeśli chcemy uzyskać ten efekt tylko dla wybranych haseł,
wtedy należy wywołać program plmindex z opcją
-r, która wyłączy standardowe grupowanie numerów stron.
Znaki specjalne
W wyżej opisywanych konstrukcjach znaki |,
|,
! i
@ miały znaczenie specjalne, jeżeli chcemy
w haśle skorowidza użyć jednego z wyżej wymienionych znaków
należy poprzedzić go znakiem " np.
aqq!aqq\index{aqq"!aqq}
wprowadzi do skorowidza hasło:
aqq!aqq, 1
Definiowanie postaci skorowidza
Program plmindex porządkując zbiór haseł wstawia szereg poleceń. Możemy mieć wpływ zarówno na ich zestaw, jak i na ich definicję. Właściwości programu możemy zmieniać na trzy sposoby:- zmienić standardowe definicje używanych poleceń (makroinstrukcji)
- Program plmindex zanurza zbiór posortowanych i posegregowanych haseł
w środowisku
index. Użycie środowiska powoduje zdefiniowanie podrozdziału o nazwie zdefiniowanej przez makroinstrukcję\indexname. Standardowo wartością polecenia jest napisIndex, jeżeli chcemy zmienić napis należy zmienić definicję tego polecenia np:\renewcommand\indexname{Skorowidz}Do definiowania sposobu prezentacji haseł na różnych poziomach używane są następujące makroinstrukcje:
| poziom | nazwa | standardowa definicja |
|---|---|---|
| 1 | \item | \par\hangindent 40\p@ |
| 2 | \subitem | \par\hangindent 40\p@ \hspace*{20\p@} |
| 3 | \subsubitem | \par\hangindent 40\p@ \hspace*{30\p@} |
- między grupy haseł (między hasła zaczynające się od różnych znaków --
ale tylko na najwyższym poziomie) jest wstawiane polecenie:
\indexspaceo wartości
\par\vskip10\p@ \@plus5\p@ \@minus 3\p@\relax - zmienić zestaw poleceń (makroinstrukcji)
-
Możemy utworzyć specjalny zbiór zawierający szereg poleceń
sterujących programem plmindex. Program plmindex wczytuje ten zbiór
jeżeli jest zdefiniowana opcja
-s(p. opcje); standardowym rozszerzeniem nazwy jest.mst. W zbiorze tym można zdefiniować następujące wartości:
| Nazwa | Wartość standardowa | Opis |
|---|---|---|
preamble string |
"\\begin{theindex}\n" | początek zbioru |
postamble string |
"\n\n\\end{theindex}\n" | koniec zbioru |
setpage_prefix string |
"\n \\setcounter{page}{" | początek polecenia definiujący zmianę wartości numeru strony |
setpage_suffix string |
"}\n" | koniec definicji polecenia zmiany numeru strony |
group_skip string |
"\n\n \\indexspace\n" | polecenie wstawiane przed rozpoczęciem grupy haseł |
headings_flag string |
0 | flaga aktywująca wstawianie poleceń przy zmianie pierwszego znaku haseł, wartość pozytywna (>0) wstawiany będzie znak w postaci dużej litery, jeśli <0 znak małej litery |
heading_prefix string |
"" | ciąg znaków, który będzie poprzedzał w.m. znak |
symhead_positive string |
"Symbols" | nazwa grupy haseł nie zaczynających się literą (wstawiany jeśli flaga >0) |
symhead_negative string |
"symbols" | nazwa grupy haseł nie zaczynających się literą (wstawiany jeśli flaga <0) |
numhead_positive string |
"Numbers" | nazwa grupy haseł zaczynających się cyfrą (wstawiany jeśli flaga <0) |
numhead_negative string |
"numbers" | nazwa grupy haseł zaczynających się cyfrą (wstawiany jeśli flaga <0) |
item_0 string |
"\n \\item " | polecenie wstawiane między dwie pozycje na poziomie 0 |
item_1 string |
"\n \\subitem " | polecenie wstawiane między dwie pozycje na poziomie 1 |
item_2 string |
"\n \\subsubitem " | polecenie wstawiane między dwie pozycje na poziomie 2 |
item_01 string |
"\n \\subitem " | polecenie wstawiane między pozycje poziomu 0 i 1 |
item_x1 string |
"\n \\subitem " | polecenie wstawiane między pozycje poziomu 0 i 1, jeśli pozycja poziomu 0 nie wystąpiła w sposób jawny (nie będzie opatrzona numerem strony) |
item_12 string |
"\n \\subsubitem " | polecenie wstawiane między pozycje poziomu 1 i 2 |
item_x2 string |
"\n \\subsubitem " | polecenie wstawiane między pozycje poziomu 1 i 2 jeśli pozycja poziomu 1 nie wystąpiła w sposób jawny (nie będzie opatrzona numerem strony) |
delim_0 string |
", " | separator między hasłem poziomu 0, a pierwszym numerem strony |
delim_1 string |
", " | separator między hasłem poziomu 1, a pierwszym numerem strony |
delim_2 string |
", " | separator między hasłem poziomu 2, a pierwszym numerem strony |
delim_n string |
", " | separator między kolejnymi numerami stron (wszystkie poziomy haseł) |
delim_r string |
"--" | separator odzielający numery zakresów stron występowania hasła |
delim_t string |
"" | ciąg znaków umieszczany na końcu listy numerów stron |
encap_prefix string |
"\\" | pierwsza część ciągu
znaków wstawiana
przy używaniu
znaku sterującego
enkapsulacji
(|) |
encap_infix string |
"{" | druga część
znaków wstawiana
przy używaniu
znaku sterującego
enkapsulacji
(|) |
encap_suffix string |
"}" | ciąg znaków zamykający polecenie enkapsulacji |
line_max number |
72 | maksymalna liczba znakow w linii (jeśli definicja hasła będzie dłuższa, zostanie przeniesiona do następnej linii) |
indent_space string |
"\t\t" | ciąg znaków wstawiany na początku ,,łamanej linii'' |
indent_length number |
16 | określenie szerokości w.m. ciągu znaków (potrzebne do prowadzenia pozycji w bieżącej linii |
- zmienić sposób działania programu plmindex definiując parametry wywołania (opcje)
-
Program plmindex posiada szereg parametrów wywołania. Ogólna
postać wygląda następująco:
plmindex [<opt>] [<idx0> ...]
<opt>mogą przyjmować jedną z następujących wartości:
Przykład:
Zawatrość zbioru .mst
delim_0 "~~"
delim_1 "~~"
delim_2 "~~"
headings_flag 1
heading_prefix "{\\par\\goodbreak\\vskip2ex\\par\\large\\bf\\noindent "
heading_suffix "}\\par\\nobreak\\vskip 1.5ex"
daje następujący efekt:
\begin{theindex}
{\par\goodbreak\vskip2ex\par\large\bf\noindent A}\par\nobreak\vskip 1.5ex
\item a~~\bold{16}, \see{odsyłacz}{16}, \bold{25}
\subitem effect~~\bold{20}
\subsubitem new~~\bold{20}
\subsubitem overlay~~\bold{20}
\subsubitem replace~~\bold{20}
\subitem href~~\bold{25}
\subsubitem \#~~\bold{19}
.
.
.
\indexspace
{\par\goodbreak\vskip2ex\par\large\bf\noindent Z}\par\nobreak\vskip 1.5ex
\item zlecenie poszukiwania~~54
\item zmiana czcionki~~28
\item znaki specjalne~~92
\end{theindex}
makroinstrukcja \bold została zdefiniowana jako:\def\bold#1{{\bfseries #1}}
| opcja | opis | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -l | podczas sortowania ignoruj spacje między słowami hasła;
np. hasło aqq bqq zostanie potraktowane
tak jak aqqbqq
| |||||||||||
| -i | jako zbioru haseł użyj standardowego strumienia (stdin) | |||||||||||
| -q | nie wyświetlaj komunikatów | |||||||||||
| -r | nie grupuj numerów stron; np. jeżeli hasło wystąpi na stronie 1, 2 i 3 to w skorowidzu nie zostanie to przedstawione jako 1-3, natomiast hasła grupowane w sposób jawny (p. grupowanie numerów stron), będą miały pogrupowane numery stron | |||||||||||
| -c | ciąg spacji i tabulatorów jest zamieniany na jedną spację | |||||||||||
| -L lang | wybór języka, determinującego porządek
leksykograficzny
| |||||||||||
| -s sty |
nazwa zbioru definicji (standardowe rozszerzenie
.mst)
| |||||||||||
| -o ind | nazwa zbiory wyjściowego (standardowo taka
jak zbiór wejściowy z
rozszerzeniem .ind)
| |||||||||||
| -? -h | wyświetlenie listy opcji | |||||||||||
| -! | opcja procedur specjalnych (zależy od
wybranego języka; dla języka polskiego
oznacza, że liczby (cyfry) będa umieszczane
w miejscu wynikającym z napisu reprezentującego
ich wartości; np. cyfra 1 zostanie potraktowana
tak jak napis jeden) (czywiście
można wymusić inną kolejność
sortowania) | |||||||||||
| -t log | log zbiór zawierający
dodatkowe komunikaty (standardowo nazwa taka jak
zbiór wejściowy z rozszerzeniem
.ilg)
| |||||||||||
| -p num | num
początkowa wartość licznika stron |
- <idx0> - zbiór haseł (standardowe rozszerzenie
.idx)
Opracował: Włodzimierz Macewicz; zmiany 05.05.2014 (StaW)